

Before a machine learning model can understand or generate human language, raw text needs to be transformed into a format it can process. This fundamental first step in Natural Language Processing (NLP) is called Tokenization. It is the process of breaking down a continuous sequence of text into smaller, discrete units called tokens. Think of it as preparing ingredients before cooking; without proper preparation, the final dish will not turn out well.
Why is Tokenization Essential?
Computers do not inherently understand words or sentences. They operate on numbers. Tokenization serves as the critical bridge, converting human readable text into a numerical representation that machine learning algorithms and neural networks can work with. Its importance stems from several key aspects:
- Numerical Conversion: Each unique token is assigned a unique numerical ID. These IDs then form the input sequences for language models.
- Vocabulary Management: By breaking text into consistent units, tokenization helps build a vocabulary, which is the complete set of all unique tokens the model knows. This manages the complexity of the language.
- Handling Linguistic Nuances: Languages are complex, with punctuation, contractions (e.g., “don’t”), and compound words (e.g., “firefighter”). A good tokenizer knows how to correctly separate or keep these units together to preserve meaning.
- Efficiency and Accuracy: The choice of tokenization method directly impacts the efficiency of language models (how quickly they process text) and their accuracy (how well they understand and generate language).
- Out of Vocabulary (OOV) Words: A common challenge is encountering rare words or entirely new words not seen during training. Tokenization methods are designed to handle these out of vocabulary (OOV) words gracefully.
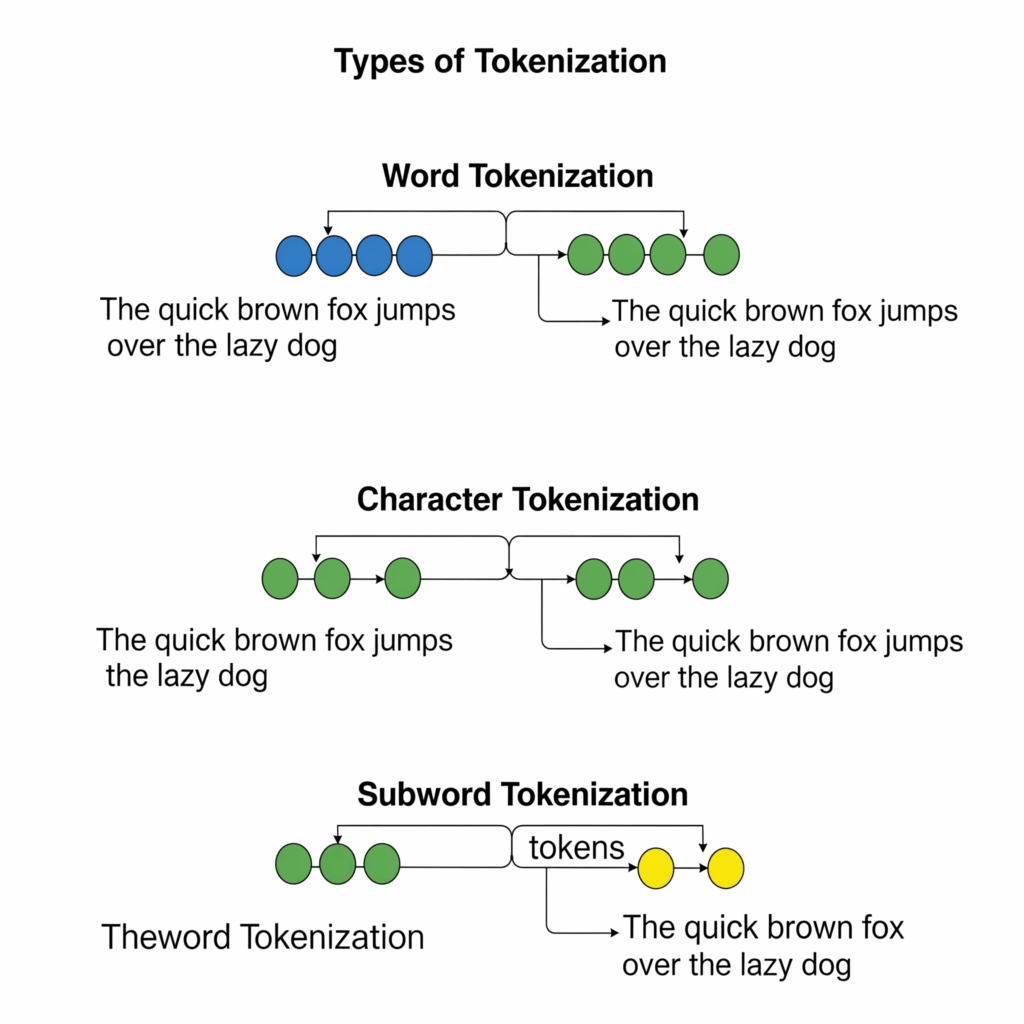
Types of Tokenization
There are several approaches to tokenization, each with its own advantages and disadvantages:
Word Tokenization
This is perhaps the most intuitive method, where text is split into individual words. It often uses spaces and punctuation as delimiters. For instance, “Hello, world!” might become [“Hello”, “,”, “world”, “!”].
- Challenges: Deciding how to handle punctuation attached to words (“dog.”), contractions (“don’t”), hyphenated words, and the sheer size of the resulting vocabulary for very large corpora.
Character Tokenization
In this method, text is broken down into individual characters. “Hello” would become [“H”, “e”, “l”, “l”, “o”].
- Pros: Completely solves the OOV problem since any word can be spelled out with characters. The vocabulary size is very small (e.g., 256 for ASCII characters).
- Cons: Loses semantic meaning at the word level, resulting in very long sequences of tokens. It is less efficient for models to capture higher level context.
Subword Tokenization (The Modern Approach)
This is the dominant method used in modern language models like those based on the Transformer architecture. It strikes a balance between word and character tokenization, offering the best of both worlds.
- Core Idea: Instead of splitting into full words or single characters, words are broken down into frequently occurring subword units. For example, “unhappiness” might become [“un”, “##happi”, “##ness”]. The “##” indicates that the subword is not the beginning of a new word.
- Algorithms: Popular algorithms include Byte Pair Encoding (BPE), WordPiece, and SentencePiece. These algorithms work by iteratively merging the most frequent pairs of characters or subword units found in the training data until a predefined vocabulary size is reached.
- Benefits: Manages vocabulary size effectively, handles OOV words by decomposing them into known subwords, and captures morphological variations (e.g., “playing” becoming “play” and “##ing”). This method is crucial for the efficiency and accuracy of large language models during pretraining and subsequent fine tuning.
The Tokenization Process and Vocabulary
A dedicated tokenizer tool is used to perform this segmentation. Crucially, this tokenizer is typically trained on the same vast amounts of training data as the language model itself. This ensures consistency between the tokenization process and the model’s understanding of the tokens. The result of tokenization is a sequence of tokens, each mapped to a unique numerical ID from the model’s learned vocabulary.
Impact on Language Models
Effective tokenization is foundational for learning robust embedding representations for words and subwords. It allows language models to generalize better to unseen words and manage the complexity of diverse linguistic inputs, ultimately powering the success of advanced NLP applications like conversational AI, machine translation, and content generation.
Conclusion
Tokenization is more than just splitting text; it is the vital preliminary step that translates the fluid nature of human language into the structured, quantifiable units required for machine processing. Its evolution, particularly with subword methods, has been key to unlocking the impressive capabilities of today’s powerful language models, making it an indispensable part of the NLP pipeline.
