Imagine teaching a computer to translate languages, understand your spoken commands, or even generate creative text. These seemingly complex tasks are often powered by a fascinating class of models known as Sequence to Sequence (Seq2Seq) models. At their heart often lie the powerful Recurrent Neural Networks (RNNs), architectures specifically designed to handle the inherent sequential nature of language and other time series data. Let’s delve into how these models work and why they’ve become so crucial in modern artificial intelligence.
The Challenge of Sequences
Traditional neural networks often struggle with sequences because they treat each input independently. However, language and many other real-world data types have a strong temporal dependency – the order of elements matters significantly. For example, the meaning of “eat apple” is very different from “apple eat”. This is where Recurrent Neural Networks (RNNs) shine.
RNNs are designed with a feedback mechanism that allows them to maintain a “memory” of past inputs in the sequence. They process one element of the sequence at a time while their internal state (their memory) is updated based on the current input and the previous state. This allows them to capture the context and dependencies within a sequence.
Sequence to Sequence Models: Mapping One Sequence to Another
Sequence to Sequence (Seq2Seq) models leverage the capabilities of RNNs (or more advanced recurrent architectures like LSTMs and GRUs) to map an input sequence to an output sequence. Think of translating a sentence from English to Urdu – the input is a sequence of English words, and the output is a different sequence of Urdu words.
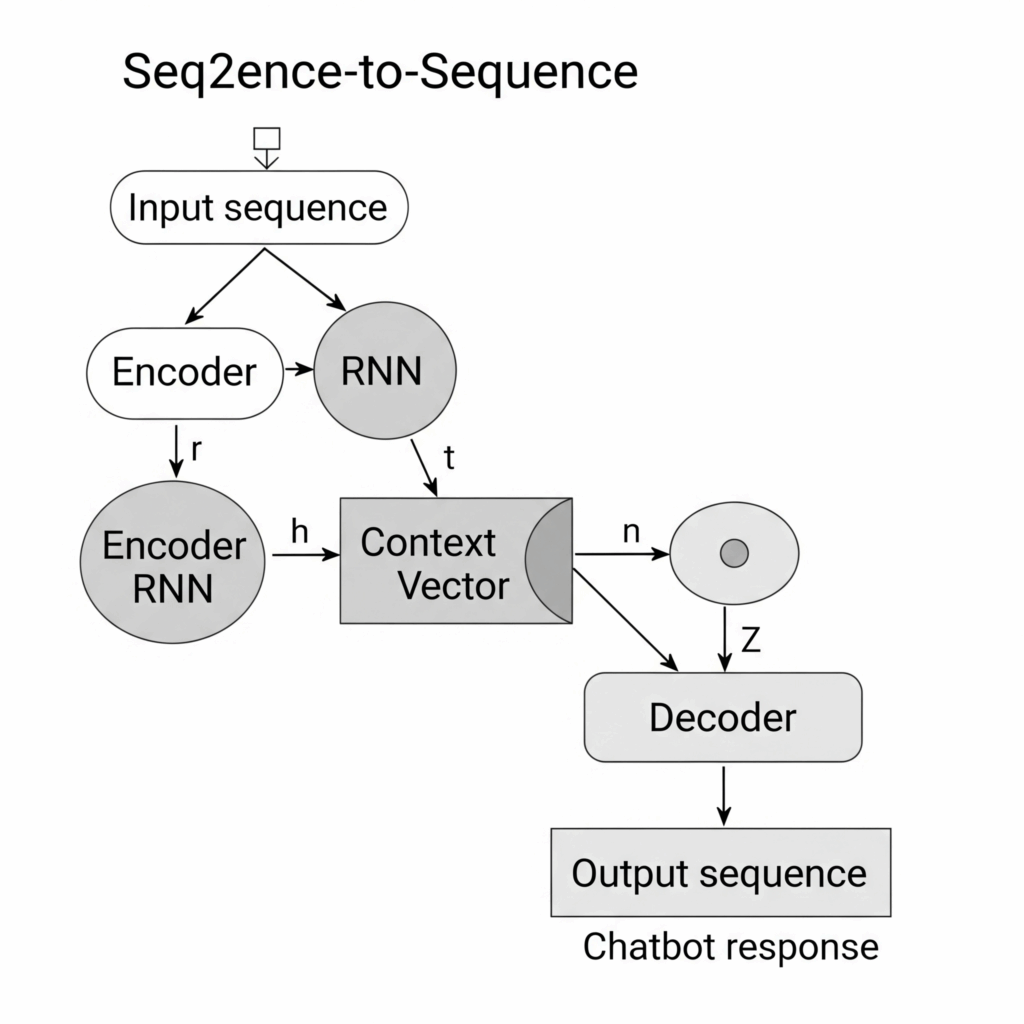
A typical Seq2Seq model consists of two main parts:
- Encoder: An RNN that processes the input sequence step by step. As it reads each element, it updates its internal state. The final state of the encoder is a compressed representation (a context vector) that captures the essence of the entire input sequence.
- Decoder: Another RNN that takes the context vector from the encoder as its initial state. It then generates the output sequence step by step, using the previously generated output as input for the next step.
This architecture allows the model to learn the complex relationships between the input and output sequences, even when they differ in length.
Why RNNs are Key to Seq2Seq
While more recent architectures like Transformers are also used in Seq2Seq tasks, RNNs (especially their more sophisticated variants) were foundational and remain important for understanding the core concepts. Their ability to maintain and propagate information through the sequence makes them well suited for encoding the input and decoding the output in a Seq2Seq framework. The hidden state acts as a crucial link, carrying the learned information from the encoder to the decoder.
Applications of Seq2Seq Models
The applications of Seq2Seq models are widespread and impactful:
- Machine Translation: Translating text from one language to another.
- Text Summarization: Condensing long documents into shorter summaries.
- Chatbots: Generating conversational responses based on user input.
- Speech Recognition: Transcribing spoken audio into text.
- Image Captioning: Generating textual descriptions for images.
Looking Ahead
Sequence to Sequence models, often powered by Recurrent Neural Networks, have been instrumental in advancing the field of AI, particularly in tasks involving sequential data. While newer architectures have emerged with their own strengths, understanding the fundamentals of Seq2Seq and RNNs provides a solid foundation for comprehending the exciting developments in natural language processing and beyond.