Large language models (LLMs) have achieved incredible feats in understanding and generating human-like text. However, their initial training primarily focuses on predicting the next word, not necessarily on being helpful, harmless, or honest. This is where Reward Model training comes into play, a critical step in aligning LLMs with nuanced human values, typically as part of Reinforcement Learning from Human Feedback (RLHF).
What is a Reward Model?
At its core, a Reward Model is a specialized neural network whose sole purpose is to act as a critic. It takes an output generated by an LLM (or a pair of outputs) and assigns a scalar score, representing how good or bad that output is according to human preferences. Essentially, it learns to mimic human judgment, providing a quantifiable “reward” signal that guides the main LLM to produce more desirable responses.
Why Do We Need Reward Models?
The challenge with directly training LLMs to be helpful is that “helpfulness” or “safety” are subjective and difficult to define programmatically. Traditional reward functions used in reinforcement learning are often too simplistic for the complexities of human language. Reward Models solve this “alignment problem” by learning subtle human preferences from actual human feedback. They transform qualitative human opinions into a quantitative score, making it possible for a policy model (the primary LLM we want to improve) to learn through reinforcement learning what outputs humans prefer. This is fundamental for AI safety and AI ethics, ensuring LLMs behave as intended.
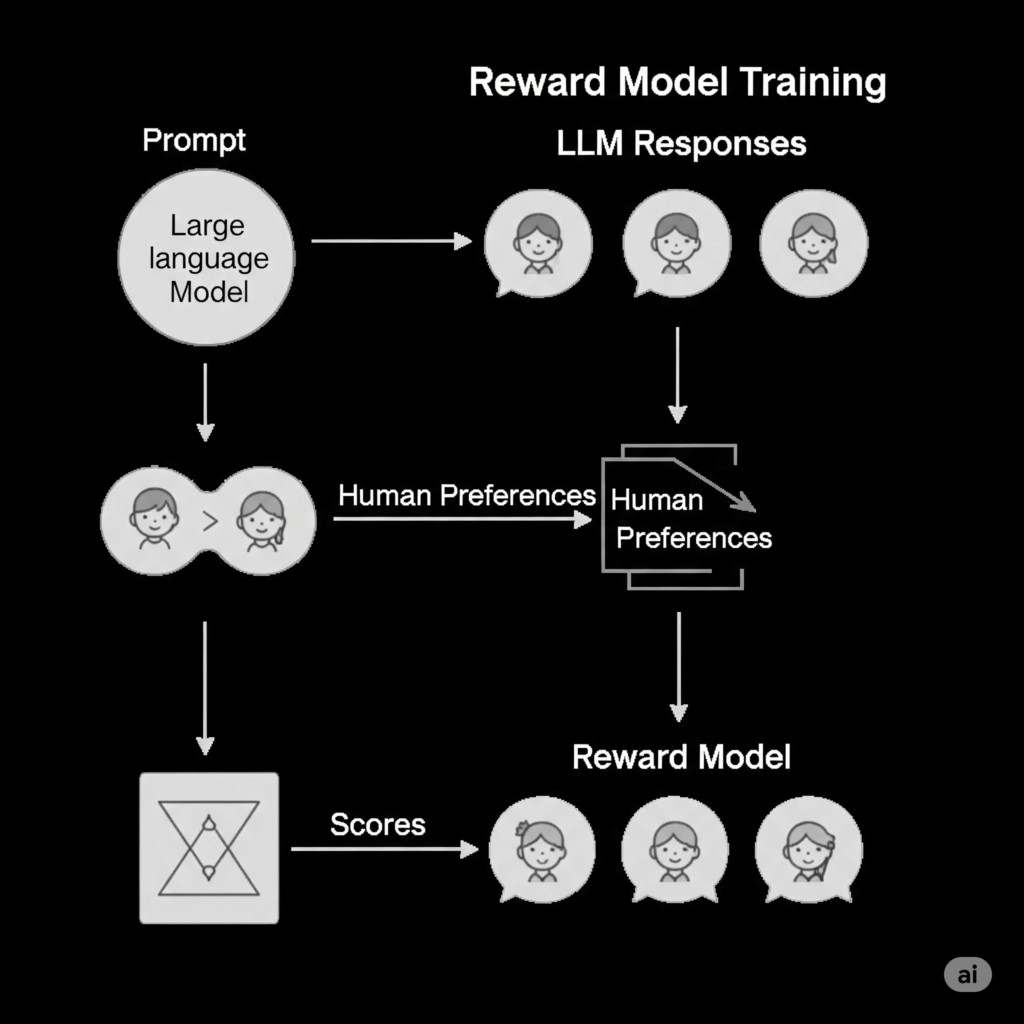
How Reward Models Are Trained
Training a Reward Model is a supervised learning task, much like fine tuning, but with a unique dataset and objective:
- Data Collection: Human Preferences: This is the most crucial step. Instead of simply labeling text, humans are presented with multiple responses from an LLM for a given prompt. They then perform pairwise comparisons, ranking or choosing which response they prefer more. This process generates a preference data set, which is the cornerstone of Reward Model training. The data indicates, for instance, “response A is better than response B.”
- Model Architecture: The Reward Model itself is typically a neural network, often initialized from a pretrained language model (though usually smaller than the LLM it will eventually score). Its final layer is modified to output a single scalar score for an input text.
- Training Loop (PyTorch): Using a framework like PyTorch, the Reward Model is trained on the collected preference data. The goal is to ensure that for any given pair of responses (one preferred, one dispreferred by humans), the model assigns a higher score to the preferred response.
- A specific loss function is used (commonly a variant of sigmoid cross entropy loss or Bradley-Terry model based loss). This loss function maximizes the difference between the scores assigned to the preferred and dispreferred responses.
- An optimizer then uses backpropagation to adjust the weights of the Reward Model, teaching it to consistently predict human preferences.
- Feedback Loop: Once trained, this Reward Model acts as a stand-in for human judgment. Its scores then become the “reward signal” used to train the original policy model through a reinforcement learning algorithm (like Proximal Policy Optimization or PPO), iteratively guiding the LLM to generate responses that are highly favored by the Reward Model, and by extension, by humans.
Challenges and Outlook
The effectiveness of a Reward Model heavily depends on the quality and diversity of the human preferences data collected. Biases in this training data can lead to unintended model behaviors. Ensuring the Reward Model truly captures nuanced human values across a wide range of topics remains an active area of research. Despite these challenges, Reward Models are a cornerstone of modern LLM alignment, enabling these powerful AIs to become safer, more helpful, and truly aligned with human intent.