Training colossal artificial intelligence models, especially the mighty large language models or transformers, is a resource intensive endeavor. While fine tuning these pretrained models on specific tasks is incredibly powerful, updating every single weight can be a memory hungry and time consuming process. Enter Low Rank Adaptation (LoRA), a brilliant technique that makes fine tuning more efficient, accessible, and ultimately, more practical.
The Challenge of Fine Tuning Large Models
Imagine trying to teach an encyclopedic brain a very specific niche topic. If you try to rewrite every single neuron connection, it takes immense effort and you might accidentally erase its vast general knowledge. Similarly, fully fine tuning a large language model often demands powerful GPU resources, consumes a huge memory footprint, and carries the risk of catastrophic forgetting, where the model loses its broad understanding. This is where Parameter Efficient Fine Tuning (PEFT) methods, like LoRA, step in.
Introducing LoRA: Low Rank Adaptation
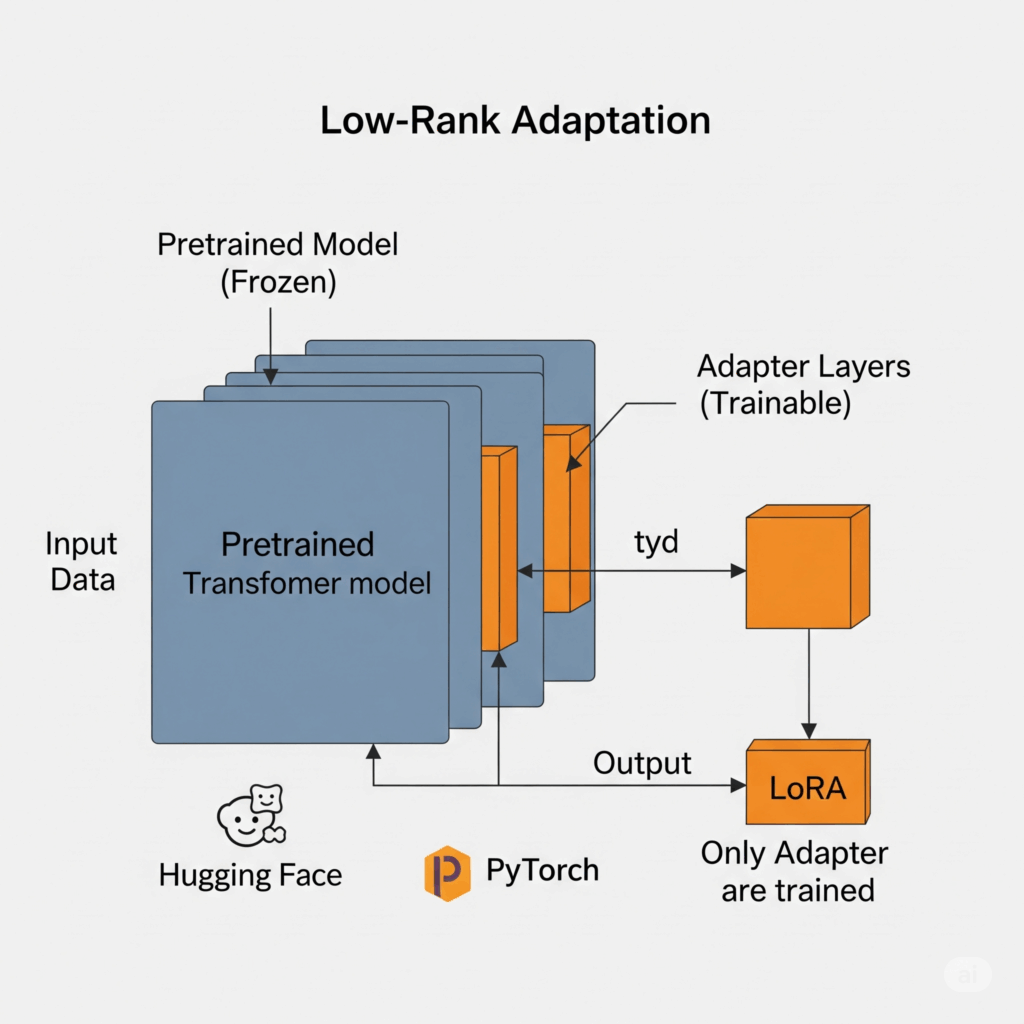
LoRA is a groundbreaking PEFT technique that dramatically reduces the number of trainable parameters during fine tuning. The core idea is elegant: instead of retraining all the original weights of the pretrained models, LoRA introduces small, trainable adapter layers alongside the existing neural network layers.
These adapter layers are “low rank,” meaning they have significantly fewer parameters than the original layers they modify. Think of it like adding a small, focused adjustment knob to a huge, complex machine, rather than rebuilding parts of the machine itself.
How LoRA Works Its Magic
During the fine tuning process with LoRA, the original, massive weights of the pretrained models are kept frozen. This means their values do not change. Instead, only the much smaller weights within the new adapter layers are updated. These adapter layers are essentially decomposed matrices (split into two smaller matrices with a low rank), which when multiplied, approximate the desired changes to the original large weight matrix.
The output of these small adapter layers is simply added to the output of the original, frozen transformer layers. When backpropagation occurs, gradients are calculated and applied only to the parameters of these tiny adapter layers. This significantly reduces the computational cost and the memory footprint required for training, making it feasible to fine tune colossal models on more modest hardware.
LoRA with Hugging Face and PyTorch
The integration of LoRA into the Hugging Face PEFT library has made this technique incredibly accessible. Developers can now seamlessly add LoRA modules to their favorite transformers models, all within the familiar and flexible PyTorch ecosystem. This means you can leverage state of the art models without the prohibitive training expenses, accelerating your transfer learning projects.
Powerful Benefits of Using LoRA
The adoption of LoRA brings numerous advantages:
- Reduced Computational Cost: Faster fine tuning cycles and less energy consumption.
- Lower Memory Footprint: Fine tune large models even on consumer grade GPUs.
- Prevents Catastrophic Forgetting: Since the base model is frozen, its general knowledge is preserved.
- Faster Inference: The added adapter layers are small and have minimal impact on inference speed.
- Efficient Deployment: You can store multiple small LoRA adapters for different task specific applications, sharing the large base model.
Conclusion
Low Rank Adaptation has transformed the landscape of fine tuning large language models, making transfer learning more efficient and accessible for a wide range of neural networks. With the powerful combination of LoRA, Hugging Face, and PyTorch, developers can now unlock the full potential of these advanced AI models for their unique challenges with unprecedented ease.