

In the world of machine learning and deep learning, particularly when working with complex neural networks, data is king. However, raw data rarely comes in a format that is immediately ready for model training. Efficiently handling and delivering this training data to your models, especially when dealing with massive datasets, is a critical challenge. This is where Data Loaders become indispensable tools.
Why Do We Need Data Loaders?
Imagine you have a dataset of millions of images or text documents. You cannot simply load all of this into your computer’s memory, let alone your GPU‘s limited memory, all at once. Even if you could, feeding individual samples one by one to a neural network would be incredibly inefficient for modern hardware designed for parallel computation. Data Loaders address several key needs:
- Memory Efficiency: They prevent overwhelming memory by loading data in smaller, manageable chunks.
- Batching: Neural networks learn best when trained on batches (or mini batches) of data simultaneously. Data loaders automatically group individual samples into these batches.
- Shuffling: To prevent the model from learning the order of your data and to ensure better generalization, it is crucial to shuffle the training data at the beginning of each training epoch. Data loaders handle this random reordering.
- Data Preprocessing and Augmentation: Raw data often needs transformations like resizing images, normalizing values, or applying data augmentation (e.g., rotations, flips) to increase dataset diversity. Data loaders allow these operations to be performed on the fly, just before feeding data to the model.
- Parallelism: Data loading can be a bottleneck, especially when your GPU is much faster than your CPU in processing data. Data loaders enable multi process loading or parallelism, using multiple worker processes to fetch and preprocess data simultaneously, keeping the GPU busy.
How Data Loaders Work: Core Concepts
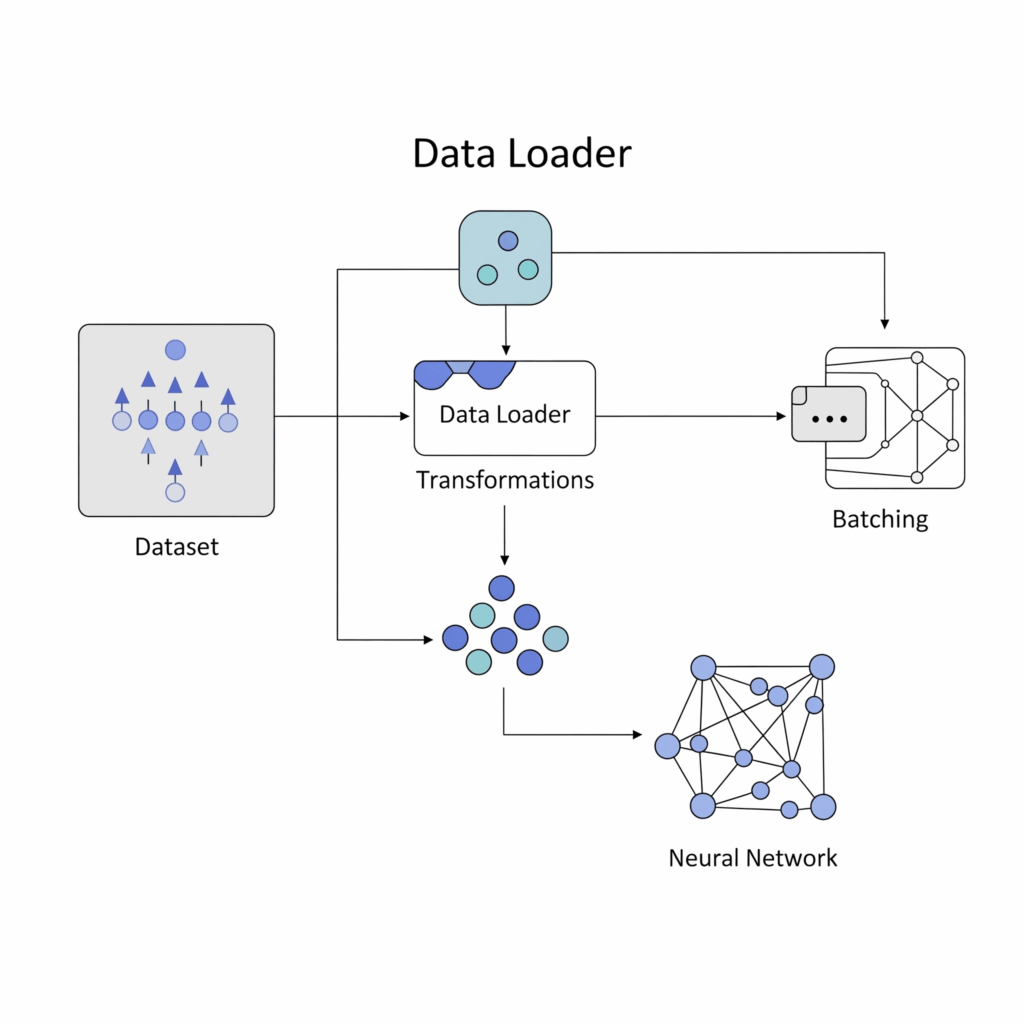
At their heart, data loaders are iterators that provide a stream of data in a structured way for model training.
- Batching: The data loader takes individual samples from your dataset and combines them into fixed sized batches or mini batches. This optimizes the computational throughput, particularly on hardware like GPUs.
- Shuffling: Before each pass through the entire dataset (known as an epoch), the data loader can randomize the order of the samples. This ensures that the model sees different combinations of data in each iteration, which helps in learning robust features and avoiding overfitting.
- Sampling: While simple shuffling is common, data loaders often support more advanced sampling strategies. This could include oversampling minority classes in imbalanced datasets or creating sequential batches for time series data.
- Parallel Loading: To speed up the data feeding process, data loaders can spawn multiple worker processes. Each worker loads and prepares a part of the data in parallel, drastically reducing the time spent waiting for data, thus improving overall model training efficiency.
Key Components in Frameworks (e.g., PyTorch)
Most modern deep learning frameworks provide robust implementations of data loaders. For example, in PyTorch, this functionality is typically split between two classes:
Dataset: This abstract class represents your entire dataset. You implement it to define how individual data samples are accessed and, importantly, how any sample specific data preprocessing or data augmentation is applied using its__getitem__method. It also specifies the total number of samples via__len__.DataLoader: This class wraps around aDataset. It is responsible for the actual iteration process. You configure it with parameters likebatch_size,shuffle=True/False, andnum_workers(for multi process loading). TheDataLoaderthen efficiently fetches, batches, shuffles, and delivers the data to your neural networks.
Benefits for Model Training
The proper use of Data Loaders provides significant advantages:
- Optimal GPU Utilization: Keeps the GPU fed with data, minimizing idle time.
- Improved Model Generalization: Shuffling helps prevent the model from memorizing the training order.
- Flexibility and Customization: Easily integrate complex data preprocessing and data augmentation pipelines.
- Scalability: Train models on datasets that are too large to fit in memory.
- Reproducibility: Control over shuffling seeds for consistent training runs.
Conclusion
Data Loaders are often unsung heroes in the deep learning pipeline. They are the essential bridge between your raw training data and your neural networks, ensuring that data is delivered efficiently, effectively, and in a manner that optimizes model training. Understanding and utilizing them properly is fundamental for any practitioner serious about building high performing machine learning models.
